
Le domaine de la data science est en constante évolution, avec des données toujours plus volumineuses et complexes à traiter. Dans ce contexte, les langages de programmation traditionnels comme Python ou R rencontrent des limites en termes de performances et de fiabilité.
C’est là qu’entre en jeu Rust, un langage relativement récent mais déjà considéré comme un nouveau titan dans l’univers de la data science. Pourquoi Rust suscite-t-il autant d’engouement dans la data science ? Cet article en parle justement.
Pourquoi Rust ?

Derrière l’essor du langage Rust se cachent trois facteurs clés qui en font un choix particulièrement adapté aux défis rencontrés par les scientifiques des données.
Ses performances exceptionnelles
En data science, l’efficacité et la vitesse sont deux facteurs primordiaux. À cet effet, Rust se distingue avec ses capacités d’exécution souvent supérieures à celles de C++.
Bien que Python soit le langage le plus utilisé en data science, Rust propose une meilleure gestion de la mémoire et une exécution plus rapide. Cette particularité vient de sa capacité à compiler le code en instructions machine de bas niveau.
L’un des exemples parfaits de la supériorité de Rust par rapport à Python et C++ réside dans sa capacité à traiter des données en parallèle. Il utilise le système de propriété pour garantir la sécurité des accès concurrents à la mémoire sans vérouillage. Ce qui accélère le traitement des données volumineuses.
Sa sûreté à la compilation
Le compilateur de Rust est capable de détecter une pléthore d’erreurs courantes avant l’exécution d’un programme. Cela inclut :
- Les erreurs dépassement de mémoire ;
- Les fuites de mémoire.
- Les conditions de concurrence.
Ainsi, le compilateur de Rust garantit un niveau de fiabilité et de stabilité élevé pour les applications critiques. En effet, un tel niveau de vérifications à la compilation est absent dans des langages comme Python. Avec Python, les erreurs ne sont découvertes qu’après l’exécution du programme.
La gestion de la mémoire sans Garbage Collector
Contrairerement à Java ou C#, Rust n’utilise pas de garbage collector pour le traitement de données en temps réel. Il emploie plutôt un système de ‘borrowing‘ et d’’ownership‘. Ce sytsème lui permet une gestion de la mémoire efficace et prévisible.
Cette approche élimine la latence occasionnée par les cycles de collecte de déchets. Elle est essentielle pour les applications nécessistant des performances en temps réel.
L’écosystème Data Science de Rust
Bien que relativement jeune, l’écosystème Rust pour la data science ne cesse de gagner en maturité. D’autant plus avec l’émergence de bibliothèques spécialisées offrant des fonctionnalités robustes pour diverses tâches clés.
Le calcul scientifique
Ici, l’on se sert de la bibliothèque ndarray quand il s’agit d’effectuer des calculs scientifiques. Cette bibliothèque est l’équivalent de Numpy en Python. Elle permet des opérations complexes de calcul avec une syntaxe claire et intuitive.
Cela inclut les opérations de base comme l’addition des matrices et les opérations complexes comme la transformation de Fourier. La bibliothèque ‘ndarray‘ met l’accent sur la performance grâce à des opérations optimisées et la possibilité d’effectuer des actions en parallèle.
Par exemple, pour créer un tableau 2D et l’initialiser avec des zéros grâce à ndarray, l’on a :
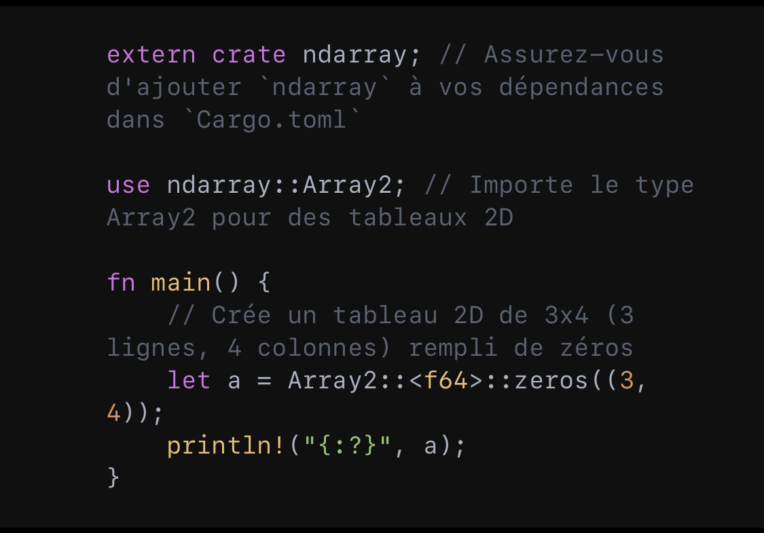

Dans le même temps, il est possible de transformer un tableau 2D en tableau 1D sans perdre de données :

En outre, ndarray supporte des calculs plus complexes tels que les opérations linéaires et non linéaires. Cela donne :
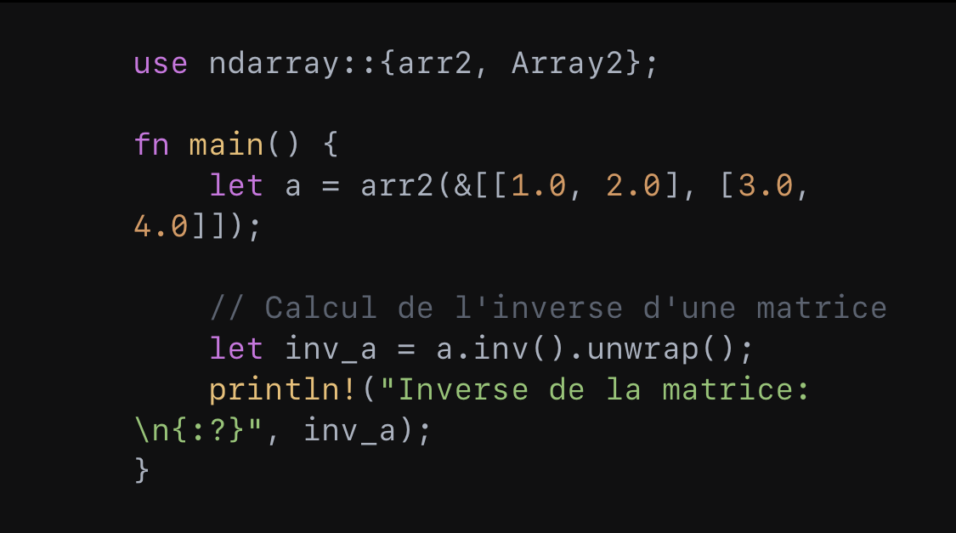
Enfin, ndarray est une librairie indispensable à Rust dans la mesure où elle permet la manipulation et l’analyse de données multidimensionnelles de manière sûre et performante.
La manipulation de données
En Rust, pour rapidement et efficacement manipuler des données, la librairie de choix est polars. Celle-ci s’apparente à pandas en Python. Mais, polars est optimisé pour des performances supérieures.
Grâce à cette bibliothèque, il est possible de trier, grouper et agréger des ensembles de données grâce à une syntaxe claire et concise. Cette performance supérieure à pandas lui provient de sa capacité à l’exécution parallèle ainsi qu’à son utilisation efficace de la mémoire.
Basiquement, polars permet de lire des données depuis un fichier CSV :
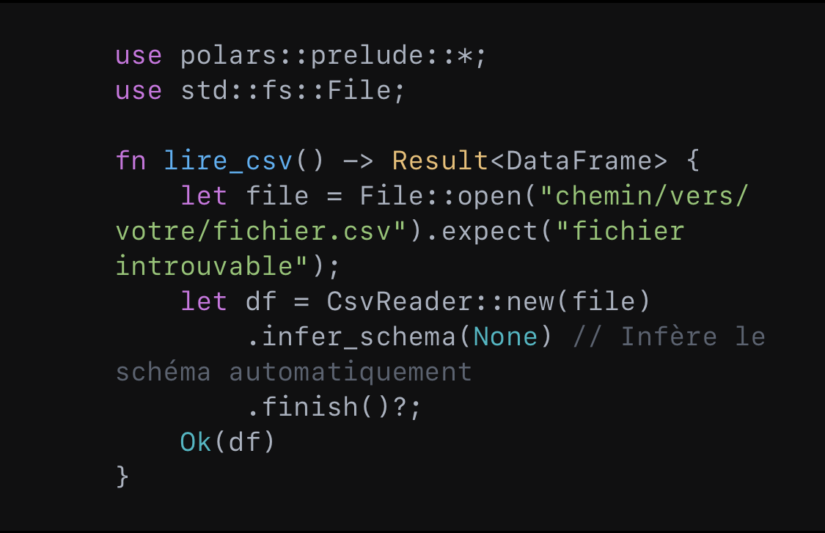
Ensuite, il peut effectuer des sélections et des filtrations une fois un DataFrame défini. Cela donne :
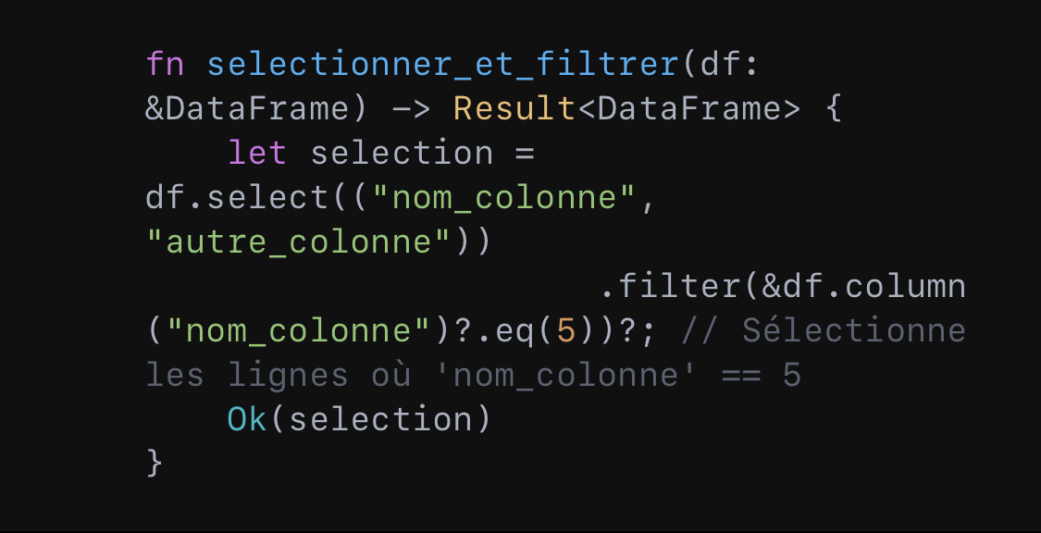
Enfin, il peut effectuer des opérations d’agrégation et de groupement. Le tout dans une syntaxe claire et efficace :
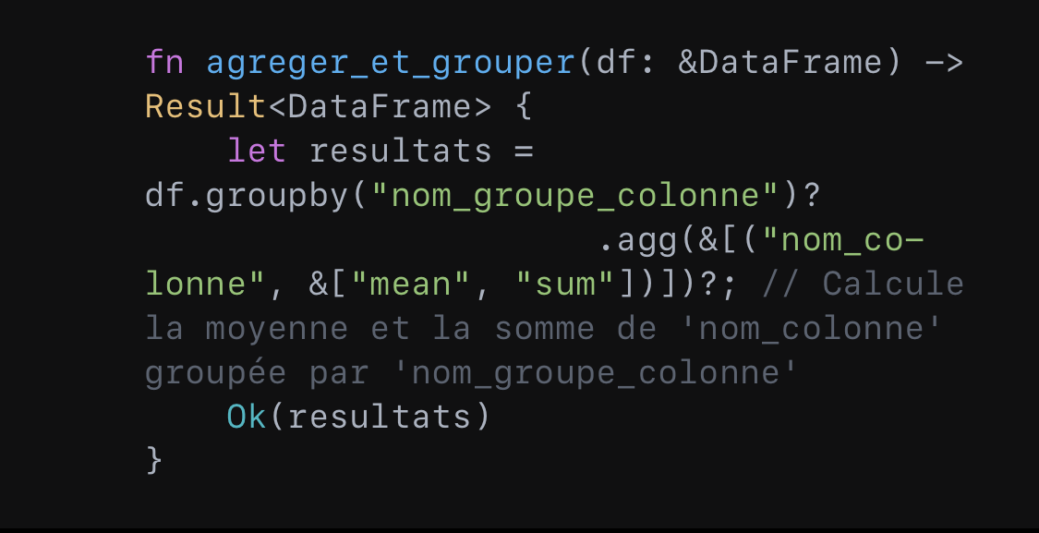
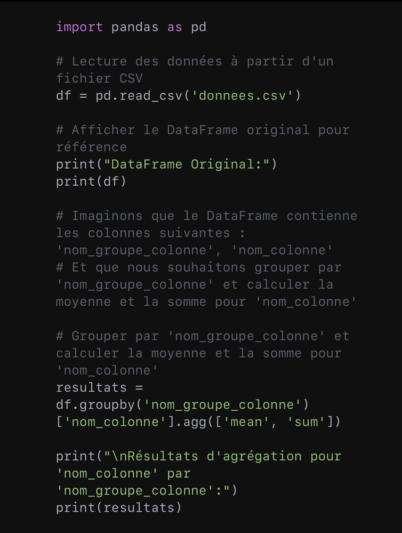
Le même exemple, en Python, donnerait :
L’apprentissage automatique
Si Python dispose d’un plus grand ecosystème pour l’apprentissage automatique, il ne peut rivaliser avec Rust en termes de performances brutes. À cet effet, la biblithèque ‘rust-ml’ vient à point nommé. Elle fournit un cadre robuste pour la construction de modèles prédictifs.
Rust-ml se démarque de librairies Python comme TensorFlow ou Scikit-Learn. En effet, elle permet aux développeurs d’intégrer l’apprentissage automatique dans des systèmes où ces aspects sont critiques.
La régression linéaire est un bon point de départ pour un cas d’usage de rust-ml. Cela donne :
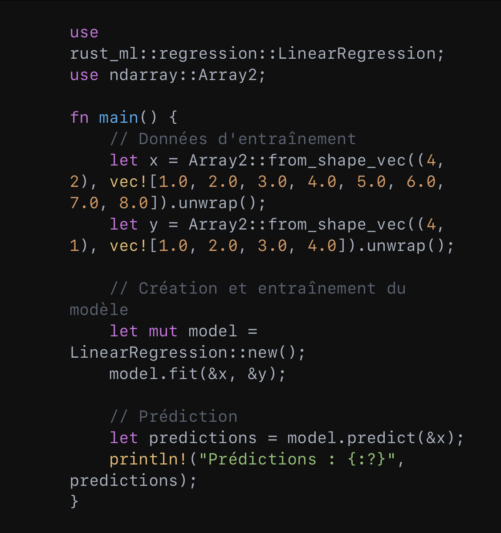
Ici, ‘x’ représente les caractéristiques d’entrée, et ‘y’ les valeurs cibles. Le modèle est entraîné avec ‘.fit()’ et effectue des prédictions avec ‘.predict()’.
Un cas plus complexe serait la classification avec l’algorithme K-Nearest Neighbors (K-NN) :
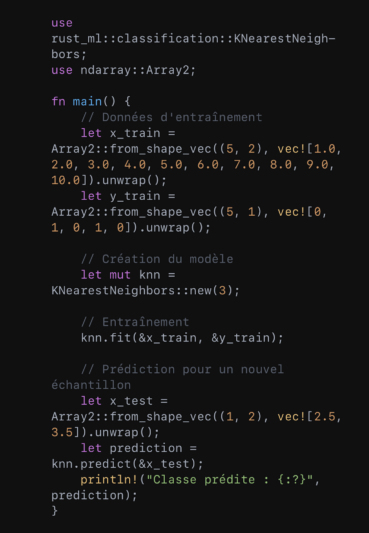
Dans cet exemple, ‘KNearestNeighbors::new(3)’ crée un modèle K-NN où K=3. Après l’entraînement, le modèle prédit la classe d’un nouvel échantillon.
L’interopérabilité avec Python
Une des particularités notables de Rust est sa capacité à s’intégrer avec d’autres langages de programmation comme Python. Cette fonctionnalité permet la collaboration fluide entre ces deux écosystèmes.
L’on peut donc combiner la facilité d’utilisation de Python et la performance de Rust. De manière pratique, cela permettrait de développer des algorithmes de calcul intensif en Rust et les exposer à un script Python pour une analyse de données ou une visualisation.
Pour assurer l’interopérabilité avec Python, les bibliothèques PyO3 et rust-cpython permettent aux développeurs d’appeler du code Rust depuis Python et vice versa.
PyO3 propose une API haut niveau qui facilite l’écriture d’extensions avec Python 3 de manière plus ergonomique et idiomatique à Rust. Ainsi, pour créer une fonction Rust avec PyO3, cela donne :
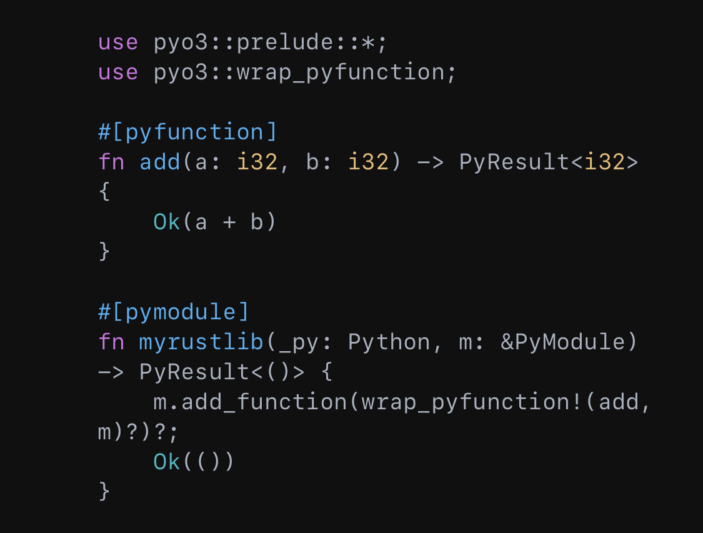
Ce code définit une fonction ‘add’ qui prend deux entiers et retourne leur somme. La macro ‘#[pyfunction]’ expose cette fonction à Python, et ‘#[pymodule]’ crée un module Python nommé ‘myrustlib’ contenant la fonction ‘add’.
En revanche, rust-cpython vise à fournir une compatibilité à la fois avec Python 2 et Python 3. Il est donc similaire à PyO3 mais avec des différences dans l’API et l’utilisation.
Soit une fonction Python ‘saluer’ qui renvoie un message de salutation. Pour appeler cette fonction Python vers Rust avec rust-cpython, l’on fait :
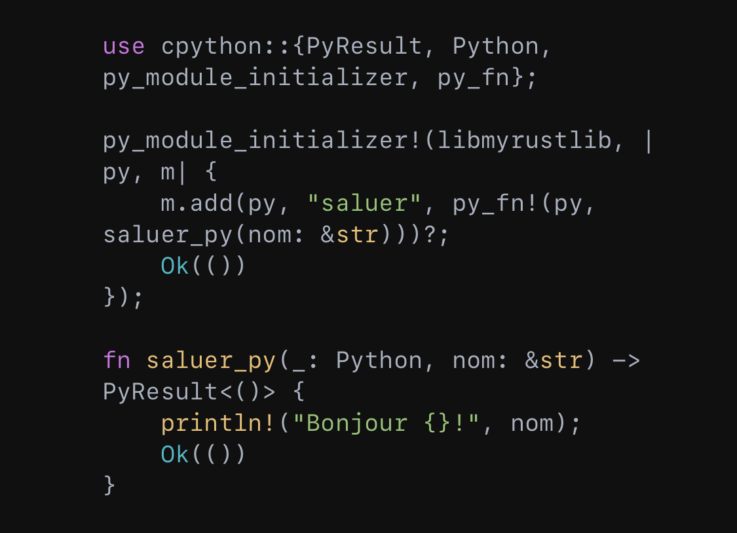
Dans cet exemple, la fonction Rust ‘saluer_py’ est conçue pour être appelée depuis Python. Elle effectue une opération similaire à notre fonction Python ‘saluer’, mais est écrite en Rust.
Défis et Limitations
Malgré ses nombreux atouts, Rust n’est pas exempt de défis et de limitations qu’il convient de prendre en compte pour une adoption réussie dans le domaine de la data science.
La courbe d’apprentissage
Contrairement à Python ou R, la courbe d’apprentissage de Rust est relativement raide. Ce langage met l’accent sur la performance et la sûreté. Cela nécessite donc une compréhension approfondie de concepts tels que l’ownership, le borrowing et la gestion manuelle de la mémoire.
Ces concepts imposent aux développeurs d’être plus conscients de la structure et du flux de leur code. Et ceci peut allonger la courbe d’apprentissage.
La taille de l’écosystème
Rust est un langage de programmation relativement récent. À cet effet, il ne jouit pas d’un ecosystème aussi vaste que celui de Python ou R, par exemple. Bien que le développement de Rust soit fulgurant, son ecosystème est toujours en pleine maturation.
Toutefois, cela ne veut pas dire que Rust ne dispose pas de librairies de qualité. C’est le cas de ndarray et polars qui tendent à equivaloir numpy et pandas, respectivement. Le problème survient lorsque le projet nécessite une large gamme de fonctionnalités.
Les ressources et la communauté
Rust possède une communauté active qui contribue à une documentation complète, des tutoriels et des forums de discussion. Néanmoins, les ressources semblent moins abondantes quand il s’agit de la data science spécifiquement.
Heureusement, il existe des cours pour apprendre les bases de Rust. De plus, des projets sur Github offrent des exemples de projets et des bibliothèques utiles.
Cependant, pour les applications spécifiques à la data science, les scientifiques de données peuvent avoir besoin de chercher plus activement des exemples de code, des tutoriels et des cas d’usage.
Comment débuter avec Rust en Data Science ?

Bien que Rust soit un langage de programmation relativement récent, il existe de nombreuses moyens pour apprendre :
- Les livres. The Rust Programming Language est la ressource la plus complète pour apprendre Rust. Encore appelé The Book, ce livre couvre tous les aspects de ce langage de programmation ;
- Les cours en ligne. Ici, l’on se tournera Exercism.io. Il propose 98 exercices pour améliorer sa compréhension de Rust via la pratique. Exercism propose une analyse automatique de son code et un mentorat personnel, gratuitement ;
- Les tutoriels. Des sites comme Medium, The Practical Dev ou Dev.to publient régulièrement des articles et des tutoriels dédiés à Rust. Ceux-ci offrent des conseils et des exemples de projet accessibles à tous les niveaux.
Enfin, il est utile de mentionner que le site officiel de Rust propose aussi des cours et tutoriels pour aider les débutants à apprendre ce langage de programmation.
Conclusion
Rust a définitivement un avenir prometteur dans le domaine de la data science. Ses performances exceptionnelles, sa sûreté à la compilation et sa gestion efficace de la mémoire en font un choix idéal pour les tâches intensives en calcul et sensibles aux performances.
Bien que son adoption reste encore limitée dans ce domaine, son écosystème ne cesse de croître avec des bibliothèques puissantes comme ‘ndarray’, ‘polars’ et ‘rust-ml‘.
Enfin, à mesure que la communauté Rust grandira et que davantage de ressources seront disponibles, ce langage pourrait bien devenir incontournable dans le paysage de la data science.

